四维计算机图形学:渲染篇
之前的文章中几乎都覆盖了目前常见的可视化四维方法:截面法、球极投影、等高面或颜色标注第四维、3D照片等,其中3D照片又分线框与体素云等展示法。这些方法想必多数读者也能理解,但如何利用计算机程序去展示它们却是一个不小的挑战。这里先介绍一些最基本的计算机图形学原理,然后深入讲解各种绘制复杂四维物体的方法。读者可以根据自己的知识水平选读。或许我后面可以开一个系列专题,专门讲解怎样一步步自己搭建一个四维图形引擎。
特色内容
- 三维计算机图形学基础
- 体素/截面四维图形渲染
- Shadertoy在线四维路径追踪演示
- 四面体法/胞腔复形法
- 体素云渲染方法
- 线框渲染遮挡剔除算法
计算机图形学基础
这里先非常粗略地介绍一下三维计算机图形学的基础知识,如果你已经非常熟悉这块内容请直接移步下一小节。想要深入了解网上的教程资源非常之多,我比较推荐这个在线课程:《GAMES101-现代计算机图形学入门-闫令琪》。
计算机如何显示图形呢?显示器本质上就是一堆排列整齐的彩灯在发不同比例强度的光,图形的本质其实就是一个二维像素阵列中储存着这些发光的强度比例的数字。为了快速计算这些动辄上十万、百万数量的像素,人们发明了显卡(GPU),不同于CPU一次执行一条单个的指令,GPU是每次接受一条指令,便同时对所有像素进行相同的运算,这样不同像素同时并行运算就比CPU一次处理一个像素快了成千上万倍。
1.光栅化技术
GPU如何计算显示三维图形呢?现在主流的做法是只绘制点、线、三角形这三种基本图形,其硬件有专门为绘制这几个图形进行优化设计,从而可以运行得非常快。下面就绘制三角形说说大致流程: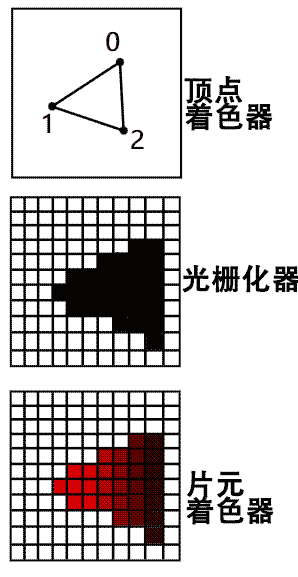
- 首先将组成几何体的三角形的顶点数据发送至GPU
- 在GPU中对所有顶点数据并行计算坐标变换,得到在画面中的透视投影的最终坐标,这段顶点坐标变换程序叫做“顶点着色器(Vertex Shader)”
- 通过硬件层面优化过的“光栅化器(Rasterizer)”快速判断图像中哪些像素属于三角形的内部,并且计算其相对于三角形的重心坐标,这部分程序是写死在硬件里的,一般不可编程。
- 对上一步确定在三角形内部的所有像素进行最终上色,这段程序叫做“片元着色器(Fragment Shader)”。注意这些像素点可以根据重心坐标信息来加以区分从而染上不同的颜色,比如通过映射到各种纹理贴图实现很多材质上的细节效果。
光栅化其实还有一些细节问题是不简单的,比如光栅化器阶段的视锥体裁剪与片元着色器阶段的遮挡剔除。
视锥体裁剪
我们之前说顶点着色器的输出是投影过后的在画面上的点的坐标其实是不准确的,因为直接绘制有严重的问题。试想有台相机位于原点,在$z=1$处放一块投影画布,根据三角形相似或解直线方程得到远处的点$p(x,y,z)$在画布上的像的位置其实是$b(x/z,y/z,1)$。 这个$1/z$的因子导致了“近大远小”这一最重要的透视现象,因此这个除以$z$的操作叫做“透视除法”,然而透视除法会带来一个很严重的问题,就是相机背后的点会跑到相机前面来,比如点$p(x,y,z)$与点$p(-x,-y,-z)$它们都会映射到屏幕上$(x/z,y/z)$同一点,然而实际上仅有位于相机前方的一个点才能被看到,因此我们要引入视锥体裁剪,并且要在透视除法之前完成。视锥体是一种表示场景中相机的视野范围的虚拟的四棱锥,位于视锥体范围外的物体是不会被绘制的。传统的GPU将投影变换与视锥体裁剪的工作放到了一起,使用一种叫“齐次坐标(Homogeneous Coordinates)”的数学工具。
这个$1/z$的因子导致了“近大远小”这一最重要的透视现象,因此这个除以$z$的操作叫做“透视除法”,然而透视除法会带来一个很严重的问题,就是相机背后的点会跑到相机前面来,比如点$p(x,y,z)$与点$p(-x,-y,-z)$它们都会映射到屏幕上$(x/z,y/z)$同一点,然而实际上仅有位于相机前方的一个点才能被看到,因此我们要引入视锥体裁剪,并且要在透视除法之前完成。视锥体是一种表示场景中相机的视野范围的虚拟的四棱锥,位于视锥体范围外的物体是不会被绘制的。传统的GPU将投影变换与视锥体裁剪的工作放到了一起,使用一种叫“齐次坐标(Homogeneous Coordinates)”的数学工具。
既然不能提前去除以这个因子$z$,人们就规定,顶点着色器需要输出一种“齐次坐标”,这种坐标把所有平行的向量视为相同的向量,即点$(x,y,z)$与点$(kx,ky,kz)$与点$(x/z,y/z,1)$都对应到画布上$(x/z,y/z)$这一个点,但显卡最终只绘制齐次坐标的第三个分量大于0的那些点,这样就避免了绘制相机背面的物体。齐次坐标不仅将非线性的透视变换变成线性的,还顺便轻松处理了视锥体裁剪。要注意的是,视锥体裁剪并不能仅仅在顶点着色器这一阶段完成,它将在光栅化阶段对每个像素进行判断,不然你没办法正确渲染那种一半位于相机前、一半位于相机后的线段或三角形。
遮挡剔除
除了剔除相机后面的物体,还需剔除被前方物体遮挡的物体。最简单的想法(叫做画家算法)是,将物体按到相机距离排序,从远到近来渲染,后上色的自动就覆盖先上色的,但事先进行排序比较繁琐,且还可能会遇到物体间两两互相遮挡的问题,因此这种事先固定一个绘制顺序的方法是不可取的。 在成熟三维渲染流程中,遮挡剔除用的是z深度缓存技术,即在每次绘制图元时,除了执行片元着色器对像素上色,还会渲染一张仅包含z轴深度信息的灰度图,叫做“深度缓存(Depth Buffer)”。在绘制下一个图元的某个像素时,将比较它与深度缓存中的深度值,若深度缓存中的深度更近,说明这个像素还在之前绘制的像素之后,则直接放弃该点的上色。之前的齐次坐标里刚好还没进行透视除法,保留了$z$轴深度信息,是不是我们就可以直接拿来用于深度缓存了呢?不是的。电脑储存数字的精度是有限的,物体可以离相机很近也可以很远,近处的细节往往比远处更重要,需要更多精度,因此与其存储深度值$z$还不如存储其倒数$1/z$来得实惠。
在成熟三维渲染流程中,遮挡剔除用的是z深度缓存技术,即在每次绘制图元时,除了执行片元着色器对像素上色,还会渲染一张仅包含z轴深度信息的灰度图,叫做“深度缓存(Depth Buffer)”。在绘制下一个图元的某个像素时,将比较它与深度缓存中的深度值,若深度缓存中的深度更近,说明这个像素还在之前绘制的像素之后,则直接放弃该点的上色。之前的齐次坐标里刚好还没进行透视除法,保留了$z$轴深度信息,是不是我们就可以直接拿来用于深度缓存了呢?不是的。电脑储存数字的精度是有限的,物体可以离相机很近也可以很远,近处的细节往往比远处更重要,需要更多精度,因此与其存储深度值$z$还不如存储其倒数$1/z$来得实惠。
现在既要遮挡剔除又要用齐次坐标做视锥体裁剪,人们规定顶点着色器输出的最终向量是一个四维齐次坐标,前两个坐标分量用于屏幕位置, 第三个坐标分量用于深度检测,第四个坐标用于透视除法。比如空间中的点$(x,y,z)$将变成$(x,y,1,z)$,做透视除法后变成$(x/z,y/z,1/z,1)$,不仅实现了相机背后剔除、正确的近大远小变换,还实现了非均匀精度的深度缓存。其实所有三角形内部需要插值的数据(比如贴图坐标等)都要在透视除法之前完成,否则会导致像下面左边的贴图那样产生透视畸变。 总结起来就是,你以为顶点着色器的输出只是屏幕上的二维点的坐标,实际上它却是一个四维的齐次坐标,这很有必要!
总结起来就是,你以为顶点着色器的输出只是屏幕上的二维点的坐标,实际上它却是一个四维的齐次坐标,这很有必要!
2.光线跟踪技术
光栅化方法的优点是快速且技术成熟,但由于绘制三角形的方式跟真实的光学成像过程并不相同,在实现复杂阴影、折反射等光学现象时将非常吃力(在视锥体裁剪与遮挡剔除这里你应该能体会到一些了)。于是另一种方法——光线跟踪诞生了。相机之所以能够拍摄到物体是因为镜头后面的感光器件接受到了光线。最直接(Naïve)的做法就是让场景中的光源均匀采样随机发射光子,模拟光线的反弹,若打到一个相机中的某个像素所在的“感光区域”则记录下该光子对颜色亮度的累加贡献。然而这个算法是非常低效的,因为相机的感光面积一般很小,很多光子最终都不会反射到镜头中,一个简单的场景可能都需要上亿个光子才能勉强得到一张能看的照片。
解决问题的方法很简单。由于光路可逆,我们可以从相机均匀采样随机发射光线跟物体反弹,只要打到光源就能倒着求出该光线所贡献的亮度,这就是最简单的路径追踪渲染方法,它能渲染出照片级质量的图像!当然它需要发射的光线也非常多,特别是光源体积很小时,击中光源的概率也非常小。这种模拟光线随机反弹的还有个副作用就是图像会产生很多噪点,要想降低噪点只能增加每个像素的采样光线数。
其实不要求照片级的真实性的话,我们完全可以在打到第一个漫反射的物体表面时就停下来,直接根据该物体的漫反射颜色计算该像素的颜色(如Lambert、Phong等光照模型),而不一定要不断随机反射追踪到照亮它的光源,这样就避免了噪点和需要采样很多光线,计算快很多,当然缺乏光线多次反弹物体看起来也假得多。
具体怎样用GPU进行光线跟踪呢?我们可以将整个图片覆盖两个三角形,伪装成光栅化渲染交给GPU,在为每个像素上色的片元着色器代码中计算光线向量与物体求交、计算颜色等操作。但GPU仅仅只能快速一次批量执行相同的指令,光线与物体相交与否会让不同的像素需要执行的后续命令大不相同,将大大降低光线跟踪在GPU上的并行计算效率,所以光线跟踪比光栅化要慢很多。为了解决这个问题人们又专门设计了能快速处理与三角形批量求交的硬件光追(如Nvdia的RTX系列)。
四维场景渲染方法
这就是三维计算机图形学基础知识了,下面我们终于可以正式介绍四维计算机图形学了。跟三维不同的是,在研究四维图形的渲染算法之前我们先得确定可视化四维图形的方法。下面我将先介绍一下使用最广泛的截面法与我最热衷的体素法。
1.体素/截面渲染
比起三维,四维场景的渲染的最大区别就是图片本身变成了一个三维的阵列,除了维数以外没有什么本质的区别,为了能在GPU上运行,我们还需要将三维阵列分层,交给GPU处理渲染得到每一层的普通二维图像,也就是截面渲染,光栅化与光线跟踪两种技术都可以完成这个任务。
1.1光线跟踪
四维光线跟踪几乎与三维一模一样,建议大家先去熟悉一下三维光线跟踪的简单片元着色器是怎么写的,推荐Shadertoy这个可以在线编辑、浏览各路大神写的着色器的网站。
一般常用的着色器语言(GLSL/WSL/HLSL)是支持四维向量vec4这个类型的,虽然它只是为表示三维齐次坐标或红绿蓝透明度四分量颜色设计的,但这刚好方便了我们表示四维坐标。光线跟踪中最重要的事就是计算光线跟物体的交点。如果只考虑与平面、球面求交,我们只需要把正常光追代码里的三维向量vec3改成四维向量vec4,第四个维度填成0,就能把场景直接升级成与超平面、超球求交!
下面是我在shadertoy上随便找到的一个路径追踪的实时渲染小场景:由于在手机浏览器上普遍加载会很卡,请慎重点击下方图片激活:
如何将这个3D场景变4D呢?首先我把其中的vec3全换成vec4,然后由于做路径追踪会遇到超球面上的均匀随机采样,需要简重新修改一下采样公式。点击这里展开分别生成方向均匀分布的单位三维、四维向量的伪代码。
我把球面均匀采样公式换成了超球采样公式,再额外添加了第四个维度上的墙体和两个超球,接着更改设置了鼠标左右拖动旋转相机,上下拖动则平移第四维的截面位置,这个4D场景Demo就被改造完成 了!提示:点击下图激活场景。

由于四维空间更广阔,点光源将立方反比衰减,光线反射也更混乱,所以相同采样率下噪点更多,需要点击三角形播放按钮后等待更长时间才能看到清晰的画质。你应该能看到上面的三维跟四维场景初始角度看起来是完全相同的(除了光线有点点差异),在四维场景中上下拖动可发现这些球大小会变化,可能消失也可能出现新的球,这些都是四维空间中的超球。还有个细节能说明光线在四维空间中传播:拖动截面到合适角度你可以通过左边的那个镜面球中的反射成像发现还没有被画面截面截到的另一个超球。
可能你觉得从三维到四维改动的东西还是不少,但其实如果不用随机反射采样而是使用那种遇到漫反射就停下来的光照模型就真的只需要把vec3改vec4就可以了。最后再提一句,由于RTX之类的光追加速显卡是专门为三维空间中三角形求交设计的,它不能对四面体求交提供加速,由于我没有真正接触过光追管线,也不排除能将四维数据“伪装”成三维数据来处理的可能(猜测可行性很小)。
1.2光栅化方法
下面来说说更常见的光栅化渲染方法。GPU能处理的基本图元——点、线、三角形,它们都是数学上的单纯形(Simplex),我们自然就想到四维场景需要光栅化四面体。但由于GPU没有针对体素化四面体进行优化的硬件,只能自己写通用的并行计算程序来实现了,我测试了我自己使用计算着色器(一种不用于渲染图形而是可以处理任意数据的GPU程序)写的四面体光栅化器效率并不太高(参考tesserxel中的这个示例)。除非你专门研发设计一款四面体光栅化专用芯片,为了尽可能利用现成的硬件性能优势,一般都采用分层渲染的方式,即计算并渲染3D图像的截面,而不是一次渲染一个四面体。所以我们将重点介绍切片光栅化方法。
不考虑复杂的光学现象,单从求图形截面与求图形投影的这两步来说,它们是可交换顺序的,即4D场景被相机拍成的3D图像的二维截面跟4D场景的3D截面再拍成二维图像的几何数据是一样的。现在,如何快速计算四维物体的截面就成了四维计算机图形学中的头号问题。计算截面的方法五花八门,我将介绍我所知道的所有方法。
四面体法
用平面去截四面体可能会得到三角形亦或四边形。我们可以通过将四面体四个顶点分别代入平面方程的一边,通过符号判断它们是否位于同侧,若4个点都在一侧则无交集,若两侧分别有1、3个点,则截到三角形,若两侧各有两个点,则截到四边形。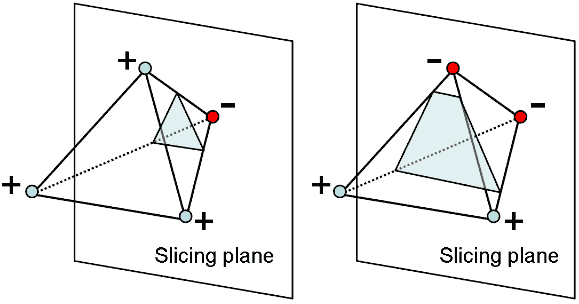
具体怎样编程实现呢?GPU没有能处理四面体截面的相关功能,所以最简单粗暴的方法就是每次渲染前,让CPU先提前计算好四维场景的截面,得到一个三维场景,然后再发送给GPU用传统3D渲染的各种技术去渲染就好了。然而它的缺点是,场景复杂后CPU计算截面的负担会特别重。我们希望在GPU上并行计算四面体截面,这样效率会显著提高。由于GPU的工作流程(渲染管线)都是为常见3D渲染设计的,并没有设计求截面的功能,我们需要通过各种技巧来实现这一功能。下面我将根据求截面使用的着色器的种类介绍三种方法。
- 顶点着色器计算截面
这是Youtuber CodeParade在游戏4D Golf中使用的算法。每个四面体为四个顶点,求截面可能得到空集、三角形或四边形,则GPU最后可能要绘制0~2个三角形,即最多会输出四个顶点。我们可以把每个四面体所有四个顶点数据打包起来复制成四份,再加上从0至3的编号作为顶点输入,这样就能让GPU在顶点着色器里运行四次计算截面的四个顶点的最终坐标了。注意由于需要判断顶点编号以及顶点是否位于平面的同侧异侧来决定最终的截面,着色器里面将会充斥着许多影响并行计算效率的条件分支语句。CodeParade采用存储一张预计算的纹理贴图,通过查表的方法来规避它们,详见这个Youtube视频。 - 几何着色器计算截面
这篇论文开发了一个叫gl4d的四维图形渲染库,采用的是另一种做法:大多数GPU渲染管线中,在顶点着色器至光栅化器之前其实还可以插入一个可选的几何着色器(Geometry Shader)。这个几何着色器可以接受顶点着色器的输入,并输出程序员可自行控制的任意数量的基本图元,直接控制输出四边形截面感觉这个着色器就像是专门为计算截面设置的!由于几何着色器是在顶点着色器之后,它接受的是由顶点着色器变换后的图元的所有顶点,因此我们需要将四个顶点坐标组合成一种图元。而已知的基本图元里面只有点、线、三角形,它们顶点数都没到4个。幸好,几何着色器的设计者早就料到了人们可能会有这些特殊需求,提供了只能作为几何着色器输入的一类特殊图元(Adjacency Primitives),如使用图元gl_lines_adjacency可以恰好将四个顶点打包扔给几何着色器计算,根据计算结果输出0至2个三角形图元(分别对应不相交、三角形截面与四边形截面),且几何着色器阶段还可以按顶点顺序做背面剔除。相比于CodeParade的方法,该方法不用把每个四面体的数据复制四次,但缺点是某些手机上的GPU可能没有几何着色器,或虽然有但执行效率不高。 - 计算着色器计算截面
由于存在设备不支持几何着色器,所以网页端的传统GPU编程接口WebGl与最新接口WebGPU干脆都没有添加几何着色器的功能,但WebGPU提供了一种新的“计算着色器(Compute Shader)”。计算着色器是为了完成除图像绘制外的通用并行计算任务而生的,比如用于大数据机器学习之类的场景。我们可以将四面体顶点数据发送给计算着色器,计算截面后得到截面的顶点数据,再将这些数据传入至传统渲染管线中的顶点着色器,从而完成后续的渲染工作。Tesserxel默认就采用的是计算着色器来处理四维物体截面。计算着色器并行地处理每一个四面体,得到0至2个三角形。我采用了一个大的数组来存放这些三角形。由于无法知道不同并行计算单元的执行顺序(不知道谁快谁慢),各个并行程序单元往大数组里写三角形时可能会存在“数据竞争(Data Race)”——即可能两个并行的四面体截面程序同时往数组的一个格子里写三角形数据,后写入的数据将覆盖掉先写入的。WebGPU提供了一种叫“原子”的操作来规避数据竞争:我们用一种“原子整数”类型的变量来存储数组下一个空闲位置的角标。第一个执行到需要读写这种原子类型的变量时,就将“锁定”它,直到它读完数据值并将变量更新为下一个空闲位置的角标(其实就是单纯角标值加一)后再“解锁”,而其它程序若执行到了需要读写被上锁的原子类型的变量,它们将在这里停下,等待变量被解锁后再执行。由于读变量和再将变量值递增一的这两步运算时间特别短,所以其它程序不会为等待解锁而浪费太多时间,并行度还是很高的。
胞腔复形法
胞腔复形(CW-Complex)是四面体法的全新升级版。试想我们要用四面体法绘制体素立方体,则先要四面体化立方体,得到最少5个四面体。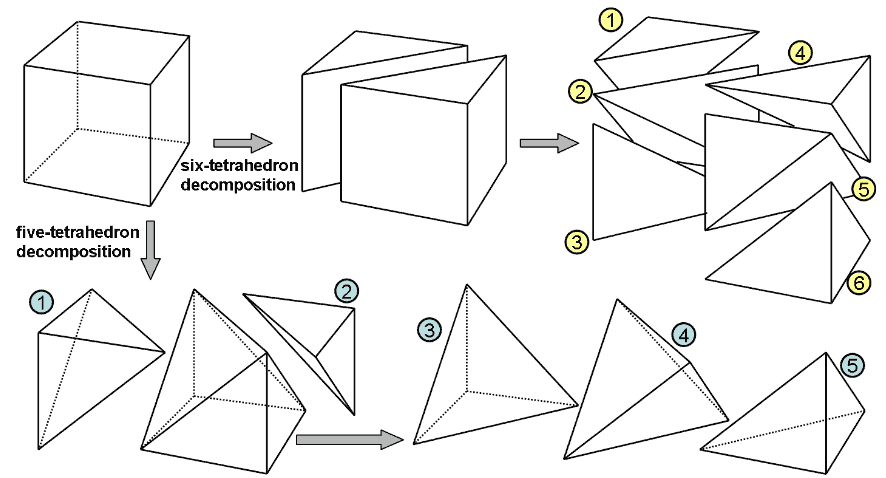 如果我们要剖分像正十二面体这样复杂的图形,四面体会多达近三十个,但正十二面体的截面最多不超过十边形,这就说明比起全用四面体,直接处理多面体、多边形将会减少很多不必要的图元。胞腔复形是多面体的推广,它提供了不采用四面体来描述四维物体的方法。胞腔复形记录了点、线、面、胞四种数据,其中顶点数据为坐标向量数组,边数据则为它的两个端点在顶点数组中的索引值,面数据中的每个面则记录组成它的所有边在边数组中的索引值,胞数据则为围成它的面在面数组中的索引值,这样层层构造出的东西就叫胞腔复形,它可以推广到任意高维。
如果我们要剖分像正十二面体这样复杂的图形,四面体会多达近三十个,但正十二面体的截面最多不超过十边形,这就说明比起全用四面体,直接处理多面体、多边形将会减少很多不必要的图元。胞腔复形是多面体的推广,它提供了不采用四面体来描述四维物体的方法。胞腔复形记录了点、线、面、胞四种数据,其中顶点数据为坐标向量数组,边数据则为它的两个端点在顶点数组中的索引值,面数据中的每个面则记录组成它的所有边在边数组中的索引值,胞数据则为围成它的面在面数组中的索引值,这样层层构造出的东西就叫胞腔复形,它可以推广到任意高维。
以上面的这个立方体胞为例,它的数据结构是这样的:(数组索引以角标形式写出来,跟上图中对应)
顶点:{(1,1,1)0,(1,1,-1)1,(1,-1,1)2,(1,-1,-1)3,(-1,1,1)4,(-1,1,-1)5,(-1,-1,1)6,(-1,-1,-1)7}
边:{(0,1)0,(1,3)1,(2,3)2,(0,2)3, (4,5)4,(5,7)5,(6,7)6,(4,6)7, (0,4)8,(1,5)9,(2,6)10,(3,7)11}
面:{(0,4,8,9)0,(1,5,9,11)1,(2,6,10,11)2,(3,7,8,10)3,(0,1,2,3)4,(4,5,6,7)5}
胞:{(0,1,2,3,4,5)0}
虽然胞腔复形的数据结构很直观,但有这么复杂层次的东西如何求它的截面呢?只要这个图形是凸的,其实也可以用分层的算法来完成这个任务:
- 首先计算所有顶点是否分别在超平面的两侧;
- 对于每条边,检查它的端点是否跨过平面,若是,计算交点坐标;
- 对于每一个面,检查它的边在上一步中有没有产生交点,若有将这些交点构造出截面图形的边。(注:若不要求图形是凸的,则交点可能不止两个,这样会得到不止两个端点的“非法”的边,算法就没法继续了)
- 对于每个胞,检查它的面在上一步中有没有产生交线,若有将这些交线构造出截面图形的面。
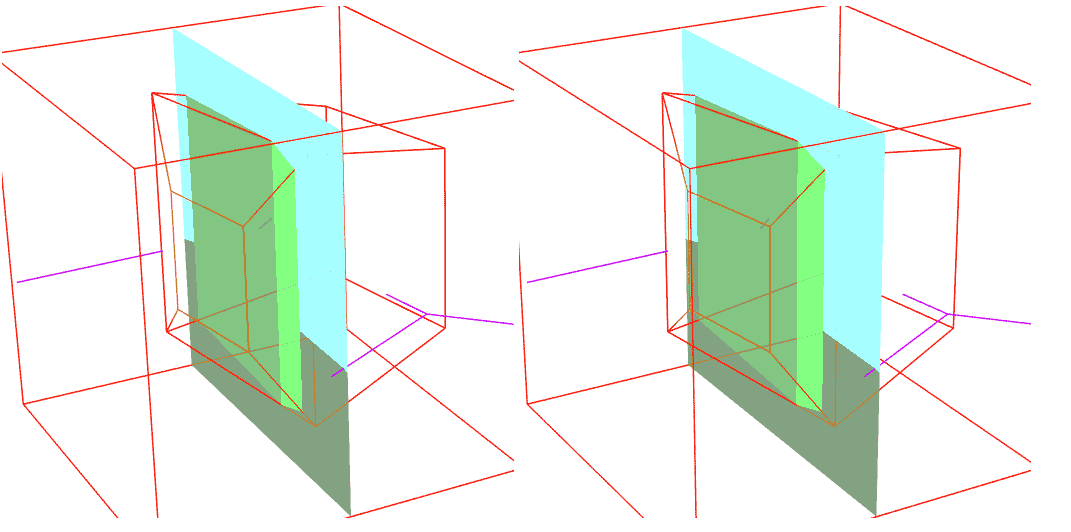
以下图立方体中蓝色截面为例,我们额外记录这样的一个结构,注意若一个胞的所有边界都没被截到,那么这个胞将被忽略,图中标成了灰色:
顶点:{+0,-1,-2,-3,+4,+5,+6,-7}
边(新顶点):{(+0,-1)0,(-1,-3)1,(-2,-3)2,(+0,-2)3, (+4,+5)4,(+5,-7)5,(+6,-7)6,(+4,+6)7, (+0,+4)8,(-1,+5)9,(-2,+6)10,(-3,-7)11}
面(新边):{(0,4,8,9)0,(1,5,9,11)1,(2,6,10,11)2,(3,7,8,10)3,(0,1,2,3)4,(4,5,6,7)5}
胞(新面):{(0,1,2,3,4,5)0}
最后要想渲染这样构造出的新的截面胞腔复形,对于非三角面还是得三角化,但取截面后三角化比起一来就四面体化产生的图元数量要少得多。如何三角化呢?由于我们假设了图形是凸的,完全可以直接选定一个顶点跟所有非相邻顶点连线即可。
虽然胞腔复形的总计算量比四面体小得多,但目前来看它只适合在CPU上运行,因为这个算法必须有顺序地从点、线再到面地串起来执行,且同一能并行计算的层级中每个面、胞的边界数一般也不同,就算并行也很难发挥出并行的效率。我很久前写的4dViewer(除Minecraft4d外)就采用的CPU计算胞腔复形截面来渲染的四维场景,在物体面数不多的情况下其实速度还可以,甚至渲染超球这些都无压力。
胞腔复形还有一个缺点就是难以表示贴图坐标(4dViewer中除Minecraft4d外的四维物体表面都是纯色,没有贴图。。)不像每个四面体直接在四个顶点上储存贴图坐标,然后通过线性插值得到内部每一点的坐标,胞腔复形的数据结构只直接包含围成胞的面的信息,并没有显式包含的顶点信息,且若一个胞的四面体剖分(或它的截面的三角剖分)方式不同,中间点插值得到的贴图坐标也会不同,因此现在我写的Tesserxel引擎不直接采用胞腔复形来表示要渲染的四维物体,只是把它作为四维建模的工具,即胞腔复形模型在渲染前必须转换为四面体,我打算在下篇讲四维图形建模的文章中再展开介绍。
输出截面顶点坐标
截面求出来后下一步就是做渲染。无论是以上哪种方法都会遇到之前的两个问题——视锥体裁剪与遮挡剔除。按三维空间的类比,渲染四维几何体需要一个五维的齐次向量,它前三个分量是体素画布上的位置,第四个是用于处理前后遮挡关系的深度缓存,最后一个则用于透视除法。目前世界上所有的GPU都是为3D渲染设计的,没有提供五阶矩阵与五维向量vec5,光栅化器的硬件层面也没有相应的处理逻辑。幸好我们只是一次绘制一个四维物体的截面,于是可以这样做:
- 首先对四面体的顶点进行坐标变换得到五维齐次坐标,由于没有提供vec5这一数据类型,我们可以用一个浮点数变量和一个vec4变量来分别储存。
- 在齐次坐标下计算截面数据(计算方法可以简单地从普通坐标系下推导过去得到),求出交点的齐次坐标。
- 假设截面垂直于体素图片的某个坐标轴。由于交点一定位于截面内,我们可以直接忽略掉现在已经无用的垂直于截面的坐标,将齐次向量维数降低成四维,作为最终顶点着色器的输出发送给GPU当成普通的三维图形处理视锥体裁剪与遮挡剔除。
对于在CPU端计算的胞腔复形来说,还有个方法能降低CPU的计算量:按理说我们需要将模型的顶点坐标变换到相机坐标再计算截面,这些操作都在CPU中进行是很慢的,其实可以优化成在CPU中先将截面方程变换到到模型坐标中直接计算截面,然后发送到GPU中再将所有顶点变换到相机坐标。
光栅化方法流程总结
我用了一个框图来总结一下这几个方法的流程:
总算把四维物体截面的光栅化渲染方法写完了,然而这些单张的截面还并不是体素照片。如何渲染体素呢?首先我们通过帧缓存(Frame Buffer)技术将单张截面画面渲染到一个纹理当中保存,再我们可以使用GPU提供的透明度混合(Alpha Blending)技术将这些单层照片贴图贴到半透明层上一层层叠起来实现,当层数够多时看起来就是体素云了。这里一般都是渲染一层就马上投影到二维画布上去做透明度混合,这样绘制下一层就可以重复使用刚才的帧缓存纹理,以节约显存。为了叠加起来得到好看的体素云,可以从以下三方面入手:
- 给场景中不同的物体赋予不同的不透明度,如地面、天空可以透明些,物体可以不透明些,这可以大大增加需要关注的小物体在体素云中的辨识度,比如下图中的“甜甜圈”几乎是不透明的了;
- 根据将体素投影到二维屏幕的方向动态改变体素切片划分的方向,一般按坐标轴分层即可,如果按任意方向分层,计算层的截面形状位置引入的开销不太值得;
- 可通过光在均匀介质中传播的指数衰减规律在片元着色器中逐像素调整不透明度,即透过每一层截面的光线比例,因为正对截面时,光线经过两层截面之间的距离短,衰减应该小、更透明,而视线与截面角度大时,经过两层截面之间的距离长,衰减应该大、更不透明。

补充:裸眼3D渲染技术
不管是4DBlock还是我的Tesserxel都支持裸眼3D,即显示一左一右两个有点偏差的画面让图片有立体深度感。之前在《四维世界(五):体验四维人的视觉与方向感》已经详细介绍过,三维立体照片的深度感方向就是立体照片的纵深,而截面画面需要的深度感方向却是第四维的离相机远近的真正的前后方向。这两种裸眼3D的实现方式不太一样。
- 三维立体照片的深度感:要获得三维立体照片的深度感,我们就需要左右两个相机在水平距离上各有一定的偏移。由于体素照片是给定的,所以渲染每个截面投影到画布时,只用绘制两次不同角度的待贴图的层叠片二不用重新渲染截面,额外绘制增加的开销可以说非常小。(但其实Alpha混合的开销不小,这个躲不掉。。)
- 单截面视图的深度感:由于这是第四维的前后深度,需要在四维场景中架设两个距离相近的相机来实现。是不是这意味着需要在两个位置把所有物体都渲染两遍呢?其实,虽然相机位置偏移,但这个偏移还是位于同一个超平面截面中(否则左右眼看到的东西就完全不一样了,无法产生立体感),所以截到的几何数据是一样的,因此可以在最后输出顶点的时候给不同的偏移即可。即先做截面再做在截面中的偏移与先做截面中的偏移在再做截面是等价的。但这就要求在四维截面的渲染管线中截面计算与最终的输出顶点的着色器在GPU中是两个步骤,否则这两步分不开也就无法节省时间了,比如Codeparade的只有一次顶点着色器就干完了所有的事情就没有这种优化的余地了。还要注意的一点是,若在计算截面阶段做了背面剔除的也不适合这个优化,因为相机视角偏差后,某些面可能正对一只眼而背对另一只眼。
体素/截面渲染就讲到这里了,下面来看看一些完全不一样的东西——非体素/截面渲染。
2.球极投影法
可视化四维图形不一定非得要计算“真实”的光线颜色信息,比如大家熟知的球极投影。球极投影本质上是把超球面——即一种弯曲的三维空间上的图形投影到三维空间,本质上就是三维空间之前的映射,严格来说不涉及四维,因此它几乎不可能用来展示复杂的“真实”四维场景,一般只用于展示四维凸几何体。
基于光栅化三角形的方法
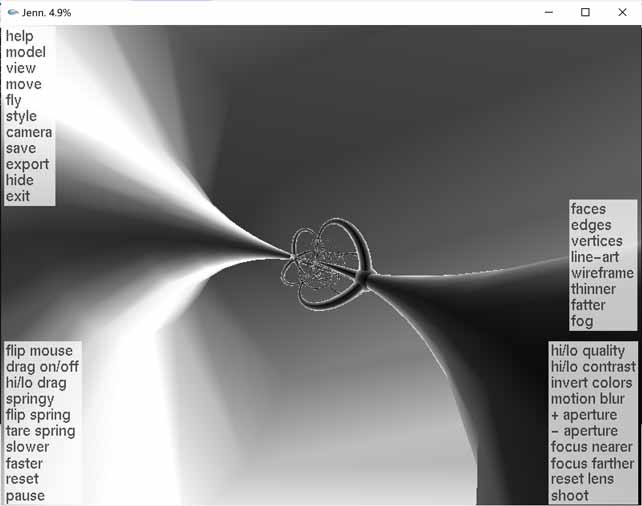
稍微会点解析几何就能很容易推出球极投影变换的公式,最简单的方法就是把超球面上的四维顶点坐标投影到三维即可,没什么特殊的地方,比如球极投影软件Jenn3D。需要注意的有两点:
- 由于原始模型都得在超球面上的坐标,要想做出有一定厚度的边、顶点等图形就需要开发者对球面几何很熟悉。
- 由于越接近北极形变越剧烈,因此建议可以动态增加北极附近多边形的网格剖分,否则就会出现下面的情况。
基于光线跟踪的方法
三角形方法得到的球极投影会因为网格精度问题变得不光滑,而高精度的光线追踪可以避免这个问题,具体原理可参考这个交互式网页和这个shadertoys上的例子(点击下方图片激活渲染,鼠标左右拖动可以选择不同的正多胞体):
3.线框渲染
由于我们人类天生就没有能同时看到三维内部所有体素的三维视网膜的眼睛,体素渲染将带来很多颜色的重叠。线框渲染可大大降低重叠的像素,让人的理解难度降低(当然这只是某方面的降低,有得必有失),所以在四维计算机图形学领域,线框渲染反而比那些带体素颜色的渲染运用得更多,比如4DBlock、dearsip与yugu233均采用该方法可视化四维物体。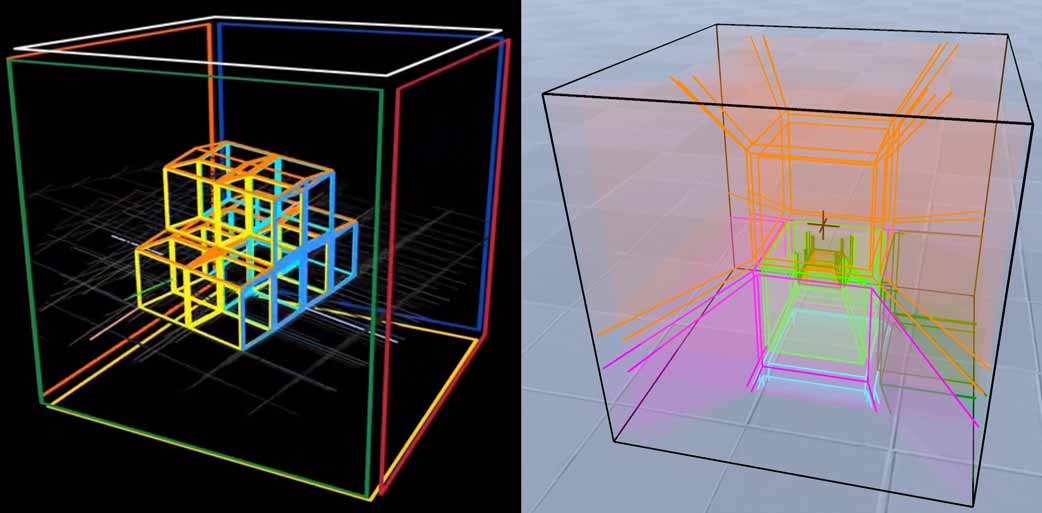
单纯渲染线框没什么好说的:首先对顶点进行坐标变换至三维相机的感光超平面上,得到类似的体素图片中的坐标,然后再将三维坐标投影到二维后,再连接各端点画出线段。但这样的算法有两个大问题——还是那两个问题——视锥体裁剪与遮挡剔除。
视锥体裁剪
由于要绘制的线段完全可能一端在相机前,一端在相机后,直接做透视投影中的透视除法将导致结果混乱。又由于不再采用光栅化方法绘制,这就要求我们要手动计算要绘制的线段与视锥体的交点,只保留相交部分。其实不只是前后,现在连上下左右侧前后也必须手动裁剪。
更棘手的问题——遮挡剔除
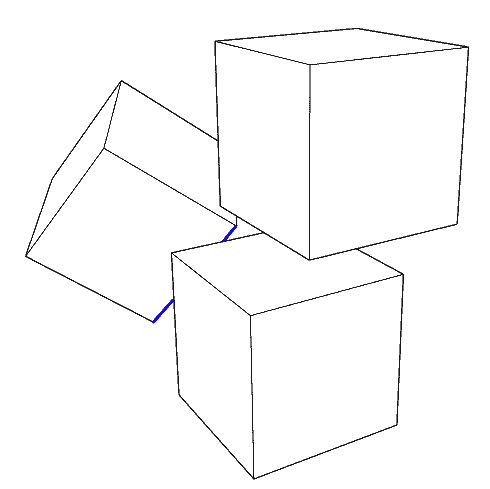
由于现在是直接在最终的二维屏幕上绘制线条,不再分层渲染,我们也没法得到深度缓存来进行遮挡剔除。于是我们必须像光线跟踪那样来解析地计算线段和每个面的遮挡关系变化处的坐标。如何做到呢?将相机看作一盏灯,每个面(胞)后面的阴影区域即为它遮挡的区域,我们的任务就是算出线段与该区域的交集并剔除掉它们。这些区域都是由超平面围成的,求解交点并不复杂,难的是判断遮挡关系,这里介绍Block4d中的算法。
对于一个$n$维凸多胞体的每个$n-1$维胞,首先通过法线判断从相机看过去是正面还是反面,然后对于凸多胞体的每条$n-2$维棱,看它是不是位于视线转角处,即看两侧的胞是否一个判断为正面另一个判断为反面。然后我们把相机与转角棱所在的超平面记录下来,再连同记录所有那些正面朝着相机的胞的超平面,我们就得到了一个无限大的锥形的遮挡区域,只要有线段位于该区域内就会被裁剪。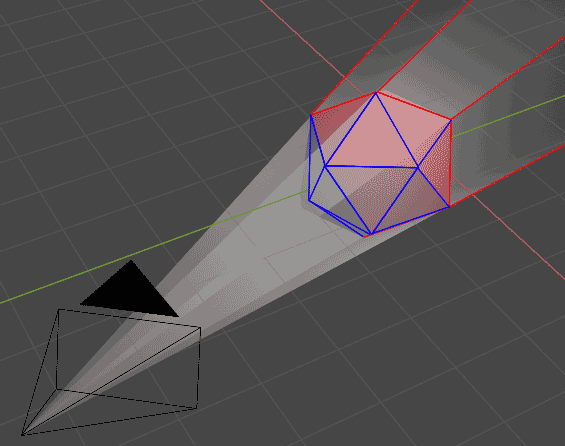 具体裁剪的思路很简单:遮挡区域是超平面围出来的,只有那些在所有超平面内侧的点才是内部点,换句话说,对于给定点,只要我们检测到它在某个超平面外,则它一定不会被裁剪。具体算法如下:
具体裁剪的思路很简单:遮挡区域是超平面围出来的,只有那些在所有超平面内侧的点才是内部点,换句话说,对于给定点,只要我们检测到它在某个超平面外,则它一定不会被裁剪。具体算法如下:
首先前面准备好了一个储存围成锥形裁剪区域的超平面数组$P$,并且法线方向已经调整至统一指向外,然后设第一个端点A的位置为0,第二个端点B的位置为1,我们准备两个临时变量$a$与$b$用于储存线段上的裁剪位置,它们之间的区域视为遮挡区域:
左端点A(0)——a—–遮挡区域—–b——(1)右端点B
初始化$a=0$和$b=1$,此时代表线段被完全遮挡:
左端点A(0=a)———遮挡区域——–(b=1)右端点B
下面我们将进入循环,对每个超平面检查线段的两个端点,逐步找到安全(即不会被遮挡剔除)的区间,慢慢压缩被裁剪的范围:
对每个锥形裁剪区域的超平面数组P的超平面p执行循环:
计算端点A、B在平面p的哪侧;
若端点A、B均在平面p外:
直接确定整条线段未被遮挡,算法结束;
若端点A在平面外、端点B在平面p内:
计算线段与平面交点的位置x;
若x>a则将a的至更新为x;(扩大确定不会被遮挡剔除的安全区间)
若端点B在平面外、端点A在平面p内:
计算线段与平面交点的位置x;
若x<b则将b的至更新为x;(扩大确定不会被遮挡剔除的安全区间)注意上面代码看似循环中有三种情况,其实隐含第四种:若两个端点完全位于超平面内,则此时没有任何有效信息,这种情况什么都不用做,只需继续循环,所以没有写出。
看似我们已经全美解决问题,但其实还有个情况,那就是当相机进入到多胞体内部时,如果想要实现下图那样的剔除,上面的算法就不再适用(此时超平面数组P为空集),此时剔除的部分刚好反过来变成了外部,算法也相应做出调整: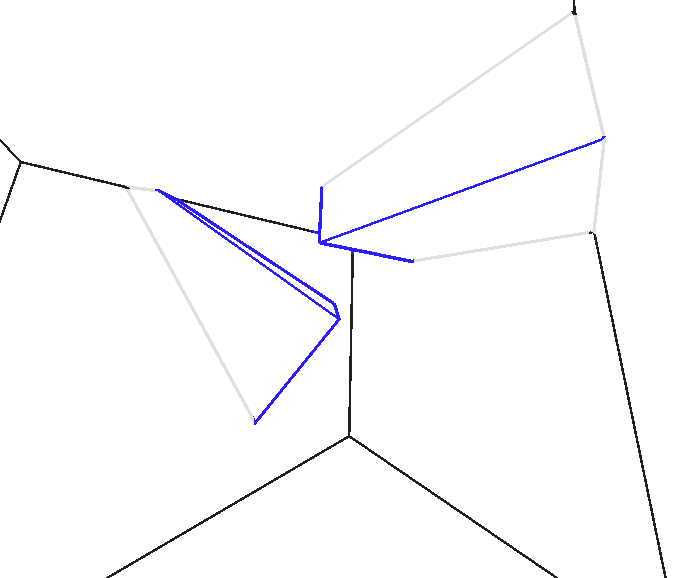
还是准备两个临时变量$a$与$b$用于储存线段上的裁剪位置,但现在中间的区域变成了没被遮挡的安全区域:
左端点A(0)—–遮挡区域—–a——–b—–遮挡区域—–(1)右端点B
还是初始化$a=0$和$b=1$,但此时却代表线段完全没有被遮挡:
左端点A(0=a)——————(b=1)右端点B
下面我们将进入循环,对每个超平面检查线段的两个端点,逐步找到要剔除的区间,慢慢压缩安全的范围:
对每个锥形裁剪区域的超平面数组P的超平面p执行循环:
计算端点A、B在平面p的哪侧;
若端点A、B均在平面p外:
直接确定整条线完全被遮挡,算法结束;
若端点A在平面外、端点B在平面p内:
计算线段与平面交点的位置x;
若x<b则将b的至更新为x;(扩大剔除区间)
若端点B在平面外、端点A在平面p内:
计算线段与平面交点的位置x;
若x>a则将a的至更新为x;(扩大剔除区间)对于场景中有多个物体的场景,我们需要在上次剔除剩下的线段之上继续进行剔除,注意相机在外部时$0 < a < b < 1$的情况对应线段剔除了中间部分被一分为二(参考遮挡剔除这一节的第一章图片中的蓝色线段),它将视为两条线段参与下一轮被其余胞遮挡剔除。最后还有个小细节:那就是为了绘制多胞体表面的棱时不要被浮点数误差误剔除,多胞体的待剔除面可以向内部缩进去一个很小的值。
以上就是线段与一个凸多胞体的剔除流程了。然而线框渲染的复杂剔除逻辑导致它能够在CPU上很好实现却难以移植到GPU中,目前我还没发现有并行化的算法,不过还是可以上一些分层的数据结构(如包围盒等)做些有限的优化。值得一提的是,dearsip还实现了三维胞对二维面的遮挡剔除,他的场景里多数都是跟坐标轴对齐的超立方体,在这个条件限制下二维面的遮挡剔除还是比较容易的,但如果要对任意形状的二维面做剔除其实是一件很复杂的事。我还没研究他的源码,不知道他是怎样实现的,等我搞懂后再补充吧。如果读者还知道其它的四维可视化方法并对其绘制原理感兴趣的,欢迎探讨。